
Codex Got Better because Claude Code Got Weird
How I stopped using Claude Code and learned to love OpenAI Codex


Codex did not win because GPT-5.5 suddenly made OpenAI unbeatable. Codex got better, yes. The bigger shift is that Claude Code started asking power users to trust a product layer that had just proven it could quietly change the behavior under their feet. Anthropic’s own April 23 postmortem says Claude Code quality reports traced back to a March 4 default reasoning-effort change, a March 26 caching bug, and an April 16 system-prompt change that hurt coding quality across Claude Code, Claude Agent SDK, and Claude Cowork (Anthropic postmortem).
That is the part that stuck.
Opus 4.7 became the face of the problem because it shipped right into that trust crater. Anthropic’s launch post says Opus 4.7 improved advanced software engineering over Opus 4.6, lifted resolution by 13% on a 93-task coding benchmark, and hit 70% on CursorBench versus 58% for Opus 4.6 (Anthropic Opus 4.7 announcement). GitHub’s Copilot changelog also described Opus 4.7 as stronger at multi-step tasks, more reliable at agentic execution, and a replacement for older Opus models in Copilot Pro+ over the following weeks (GitHub Changelog). The official story was clean. The user story was a mess.
The regression story power users actually told
The most useful artifact in this whole blowup was Stella Laurenzo’s GitHub issue on anthropics/claude-code, because it turned a bunch of “Claude feels dumber” complaints into measurable behavior. Laurenzo’s report analyzed 6,852 Claude Code session files, 234,760 tool calls, and 17,871 thinking blocks, then argued Claude Code had stopped doing the kind of extended reasoning needed for senior engineering work (GitHub issue #42796).
The numbers were brutal. Median thinking depth dropped about 67%, read-to-edit ratio fell from 6.6 reads per edit to 2.0, edits without prior reads rose from 6.2% to 33.7%, and user interrupts per 1,000 tool calls rose from 0.9 to 5.9 in the degraded window (GitHub issue #42796). The same issue estimated daily cached Bedrock cost rising from about $12 to $1,504 in the bad period, which is the kind of number that makes “it feels worse” suddenly become a procurement problem (GitHub issue #42796).

Caption: The interesting part was not that users complained. It was that power users measured the behavioral shift, then Anthropic confirmed product-layer causes.
Anthropic later confirmed the broad shape of that failure, even if it did not frame it as model-weight regression. The postmortem says the March 4 reasoning change moved Claude Code defaults from high to medium, the March 26 caching bug made Claude forgetful and repetitive in stale sessions, and the April 16 prompt change added tight text-length limits that hurt coding quality; Anthropic says all three were fixed by April 20 and subscriber usage limits were reset (Anthropic postmortem).
That last detail cuts both ways. Anthropic fixed the immediate bugs. It also confirmed that the thing users were complaining about was real.
VentureBeat’s coverage captured the same arc from the outside: developers across GitHub, X, and Reddit reported Claude getting worse at sustained reasoning, more wasteful with tokens, and more likely to choose a lazy edit-first path instead of reading enough context first (VentureBeat). VentureBeat also reported that the Claude API was unaffected and that the underlying weights had not regressed, which helps only if you are benchmarking a raw model and not trying to ship a feature through Claude Code at 1 a.m. (VentureBeat).
Opus 4.7 was probably the wrong villain
The cleaner read is that Opus 4.7 walked into a product-layer fire. Reddit threads blamed the new model directly, with users describing it as verbose, slow, overthinking, token-hungry, and weaker than 4.6 for some writing and coding-adjacent tasks (Reddit r/Anthropic). Another Reddit thread on Claude Code cost said an Opus 4.7 workflow on a $100 plan could hit limits in about 1.5 hours of continuous xhigh work, while a prior Opus 4.6 workflow usually consumed about 60% of the weekly allowance and only sometimes hit limits during a 5-hour session (Reddit r/ClaudeCode).
There is a reasonable counterargument from Claude power users: Opus 4.7 is better when used as a planner or advisor, and it gets expensive when people run it as the primary executor through long tool-call loops. A Substack post made that case directly, arguing that Opus 4.7 “shipped as an advisor, not an executor,” and that Sonnet should hold the keyboard while Opus gets called for planning, architecture, and judgment calls (Claude Code for Non-Coders).
I buy part of that. Expensive thinking models should not be used to shovel boilerplate through a 60-call bash loop. Still, the product failed if a normal heavy user could upgrade, keep the same workflow, and suddenly burn the ceiling by Tuesday. A coding agent is a harness, defaults, docs, rate limits, prompts, memory, file reads, edit policy, and model behavior smashed together. Users do not experience those layers separately.
Codex started feeling like the adult in the room
Codex’s advantage in these threads is boring in the best way. It reads more. It plans more. It obeys repo-level instructions more reliably. It tends to make fewer weird unilateral edits.
One Hacker News user wrote a detailed comparison around a many-years-old Python monolith with newer DDD-ish code, older structured legacy code, and fragile spaghetti code. That user preferred Codex because it followed harness-engineering principles better, searched existing code before inventing new tools more often, and asked clarifying questions before making architectural changes more often than Claude Code (Hacker News).
That maps almost perfectly to OpenAI’s own “harness engineering” essay. OpenAI describes Codex workflows built around short AGENTS.md files, execution plans, repo-local docs, structural tests, logs, metrics, isolated worktrees, agent-to-agent review loops, and mechanical guardrails that make the repo legible to the agent (OpenAI harness engineering). The core lesson in that piece is plain: the agent gets better when the repo becomes an environment it can inspect, validate, and repair instead of a pile of context dumped into a prompt (OpenAI harness engineering).
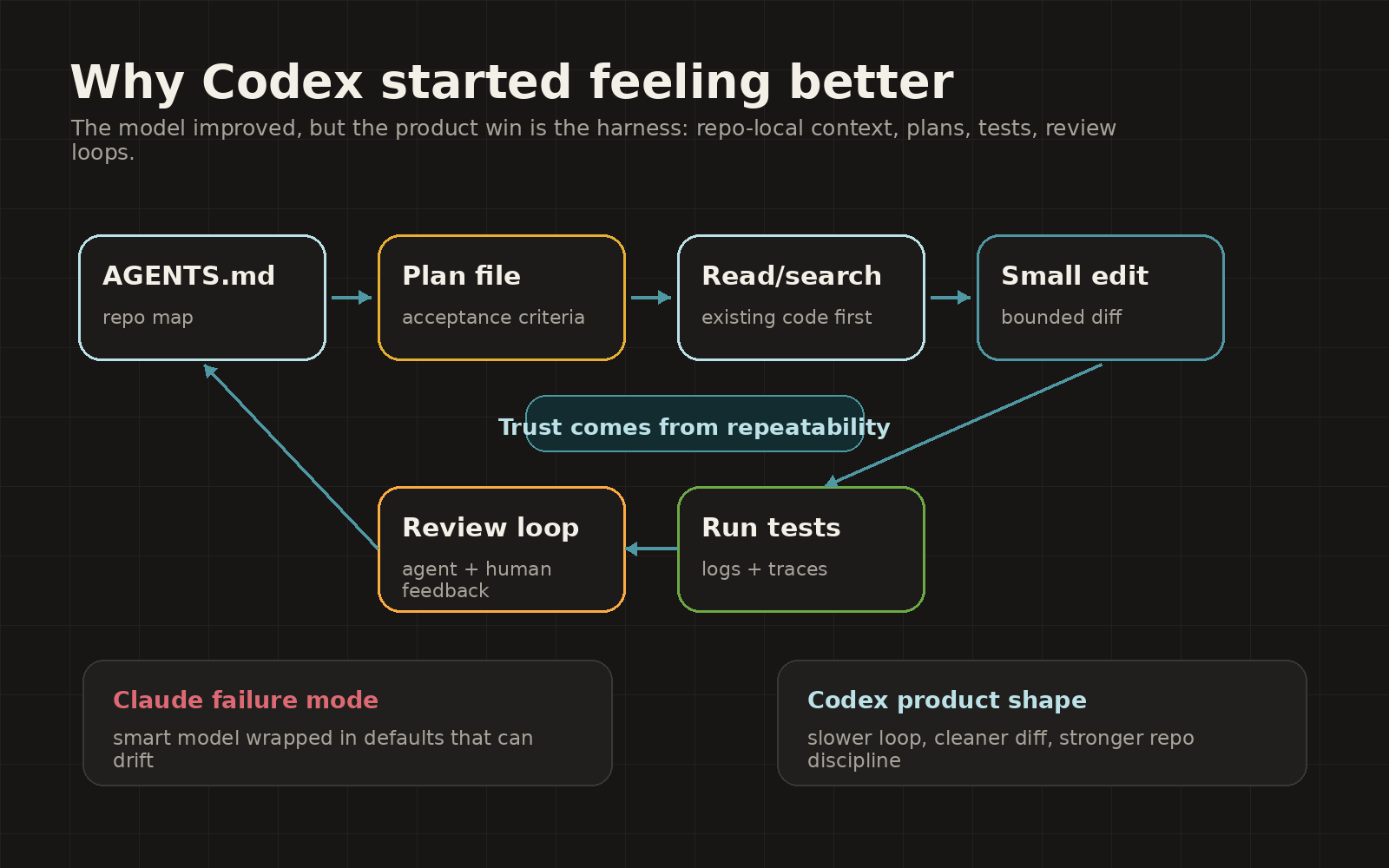
Caption: Codex’s edge is less mystical than people make it sound. The harness makes the repo legible, forces repeatable loops, and turns “smart model” into “usable engineering process.”
That is also why Codex looks better to backend and infrastructure people right now. They do not need a charming pair programmer. They need a stubborn process that reads the repo, respects the plan, runs the tests, opens the PR, takes review, and does not invent a new abstraction because it saw a shiny pattern in one file.
Reddit users have been saying the same thing in less polite language. In a Claude Code subreddit comparison based on about 100 hours with Claude and 20 hours with Codex on an 80,000-line Python/TypeScript project with 2,800 tests, the poster said Claude was faster and more interactive, while Codex was slower, more methodical, and produced higher-quality work (Reddit r/ClaudeCode). The same post said Claude needed more supervision, sometimes ignored CLAUDE.md, and occasionally left migrations incomplete, while Codex treated AGENTS.md directives as stable constraints and paused to reassess assumptions without being asked (Reddit r/ClaudeCode).
Builder.io’s comparison lands in the same general place from a product angle. Steve Sewell wrote that his personal winner was Codex, largely because Codex had better GitHub integration and pricing, while Claude Code still had the stronger terminal UX, more configuration depth, hooks, and slash commands (Builder.io). Builder.io also reported that its users rated GPT-5 Codex 40% higher on average than GPT-5 Mini and Claude Sonnet, and that Codex’s GitHub app found legitimate hard-to-spot bugs while the team found Claude Code’s GitHub reviews verbose and weak at catching obvious bugs (Builder.io).
GPT-5.5 gave Codex the missing shove
Codex already had a process story before GPT-5.5. GPT-5.5 made the story easier to believe.
NVIDIA says Codex is now powered by GPT-5.5 and that more than 10,000 NVIDIA employees across engineering, product, legal, marketing, finance, sales, HR, operations, and developer programs have been using GPT-5.5-powered Codex (NVIDIA). NVIDIA also says debugging cycles that used to take days are closing in hours, experimentation that used to take weeks is turning into overnight progress in complex multi-file codebases, and teams are shipping end-to-end features from natural-language prompts with fewer wasted cycles than earlier models (NVIDIA).
Take the enterprise hype with the usual salt. NVIDIA is not a neutral observer in a story about OpenAI models running on NVIDIA infrastructure, since its article explicitly ties GPT-5.5-powered Codex to NVIDIA GB200 NVL72 systems and OpenAI’s NVIDIA-heavy infrastructure plan (NVIDIA). The story still lines up with the social signal from Reddit and Hacker News: Codex feels slower than Claude in the moment, then often comes back with work that needs less babysitting (Reddit r/ClaudeCode, Hacker News).
The funny twist is that some users now want Claude Code as the shell and GPT-5.5 as the engine. A Reddit thread described running Claude Code through a local Anthropic-compatible proxy backed by Codex/GPT-5.5 auth, keeping Claude Code’s terminal workflow while swapping in GPT-5.5 underneath (Reddit r/ClaudeCode). One commenter in that thread pushed back that the Codex native application beats the Claude native app, while the original poster framed Claude Code as the preferred terminal interface with GPT-5.5 as the model layer (Reddit r/ClaudeCode).
That is the product indictment hiding inside the hack. People are trying to unbundle the agent shell from the model because neither vendor has nailed both at the same time.
The Hacker News verdict was harsher than the benchmark story
Benchmarks still make Claude look strong. Anthropic claims Opus 4.7 beat Opus 4.6 on advanced software engineering tasks, CursorBench, Rakuten-SWE-Bench, visual acuity, complex workflows, and several customer evals (Anthropic Opus 4.7 announcement). GitHub’s Copilot changelog says Opus 4.7 brings stronger multi-step task performance and more reliable agentic execution, even as its premium request multiplier later moved to 15x after promotional pricing ended (GitHub Changelog).
Social trust was harsher. In an Ask HN thread titled “Is it just me or is Claude Code getting worse?”, one user wrote that OpenAI’s Pro plan on an OpenCode harness with GPT-5.5 XHigh and parallel delegation “absolutely smokes Claude Code 4.7 Max,” while also conceding that Opus 4.7 Max API might be slightly better than GPT-5.5 XHigh but not enough to justify the price (Hacker News). Another commenter in the same thread said the latest Claude Code felt “lobotomized,” and another blamed Claude Code’s prompt and harness for requiring too much coercion to keep agents aligned with repo instructions (Hacker News).
That is why this discourse is so dangerous for Anthropic. Once developers start separating “raw model is smart” from “product is reliable,” benchmark wins stop closing the argument. You can have the better model and still lose the workflow.
My read
Codex has become the better product for a specific class of user: backend-heavy, repo-heavy, test-heavy engineers who want an agent to operate inside a harness and come back with a defensible diff. The strongest evidence comes from the HN production-monolith writeup, the Reddit long-project comparison, Builder.io’s product comparison, and OpenAI’s own harness-engineering direction (Hacker News, Reddit r/ClaudeCode, Builder.io, OpenAI harness engineering).
Claude Code is still probably better for some UI, design, exploratory planning, and ambiguous product work. The HN monolith poster explicitly said Opus 4.6 was much better for frontend work than Codex 5.3 and GPT-5.4 in their experience, and Builder.io still gives Claude Code the edge on UX and configuration depth (Hacker News, Builder.io).
Opus 4.7 also may be a better model than angry Reddit makes it sound. Anthropic’s own benchmarks show real gains over 4.6, and the advisor-not-executor argument is technically plausible for workflows that call Opus only when the problem deserves expensive reasoning (Anthropic Opus 4.7 announcement, Claude Code for Non-Coders).
The product problem remains. If the best way to use Opus 4.7 is “actually, don’t use it as the main coding agent,” then Claude Code needs to make that architecture obvious, cheap, and hard to misuse. If a user has to read three posts, switch aliases, understand hidden effort settings, and manually reason about token economics to avoid torching their plan, Codex does not need to be smarter. It just needs to be less weird.
That is why Codex feels like it somehow passed Claude Code. OpenAI shipped a coding product whose defaults increasingly line up with how agentic engineering needs to work: plans, repo-local instructions, background execution, code review, tests, and review loops. Anthropic shipped a stronger Opus and then let the product layer teach users that the floor could move.
For developers, trust is part of intelligence now. A coding agent that reads before editing, follows the plan, respects the repo, and fails in boring ways will beat a genius model wrapped in unstable defaults.
The missing piece in this article is that Anthropic didn't actually fix the issue. The underlying cause of the thinking regression wasn't a default setting, it was the fact that adaptive thinking became forced by default. Adaptive thinking is now the ONLY option in 4.7, making it MUCH worse in longer context work.
I work with small business owners on AI automation every week and this competitive dynamic between tools is exactly what drives adoption. Practical AI for business improves fastest when the pressure is real. What workflow changes from these improvements are you finding most impactful in day-to-day use?