
Context is the Only Lever
Engineering the attention budget for coding agents


35,000 lines of Rust shipped in a single seven-hour session. Two features the maintainers had estimated at three to five senior-engineer days each. An intern shipping ten PRs on day eight. Dex Horthy’s HumanLayer team did this with the same models you have. The only thing they did differently was manage context ruthlessly.
Horthy’s Advanced Context Engineering for Coding Agents came out eight months ago. In AI-tooling time, that’s ancient. But the core argument held up better than most things published that week, and it’s worth distilling before layering on what the last few months of research added.
The HumanLayer argument
Coding agents struggle in real production codebases. The Stanford developer-productivity study Horthy cites found that AI tools help on greenfield work and small edits, but often make engineers slower in large brownfield repos. Rework eats the gains.
Horthy’s counter: you can get very far with today’s models if you take context engineering seriously as an engineering practice. His team shipped 35k LOC to BAML, a 300k-line Rust codebase, in that single seven-hour session.
The technique he calls frequent intentional compaction.
Why context is the only lever
An LLM turn is a stateless function. Context window in, next step out. Without training new weights, the only thing you can affect is what lives in that window. So you optimize for:
Correctness of the information in context
Completeness
Size
Trajectory
And you avoid, in order of severity: incorrect information, missing information, too much noise.
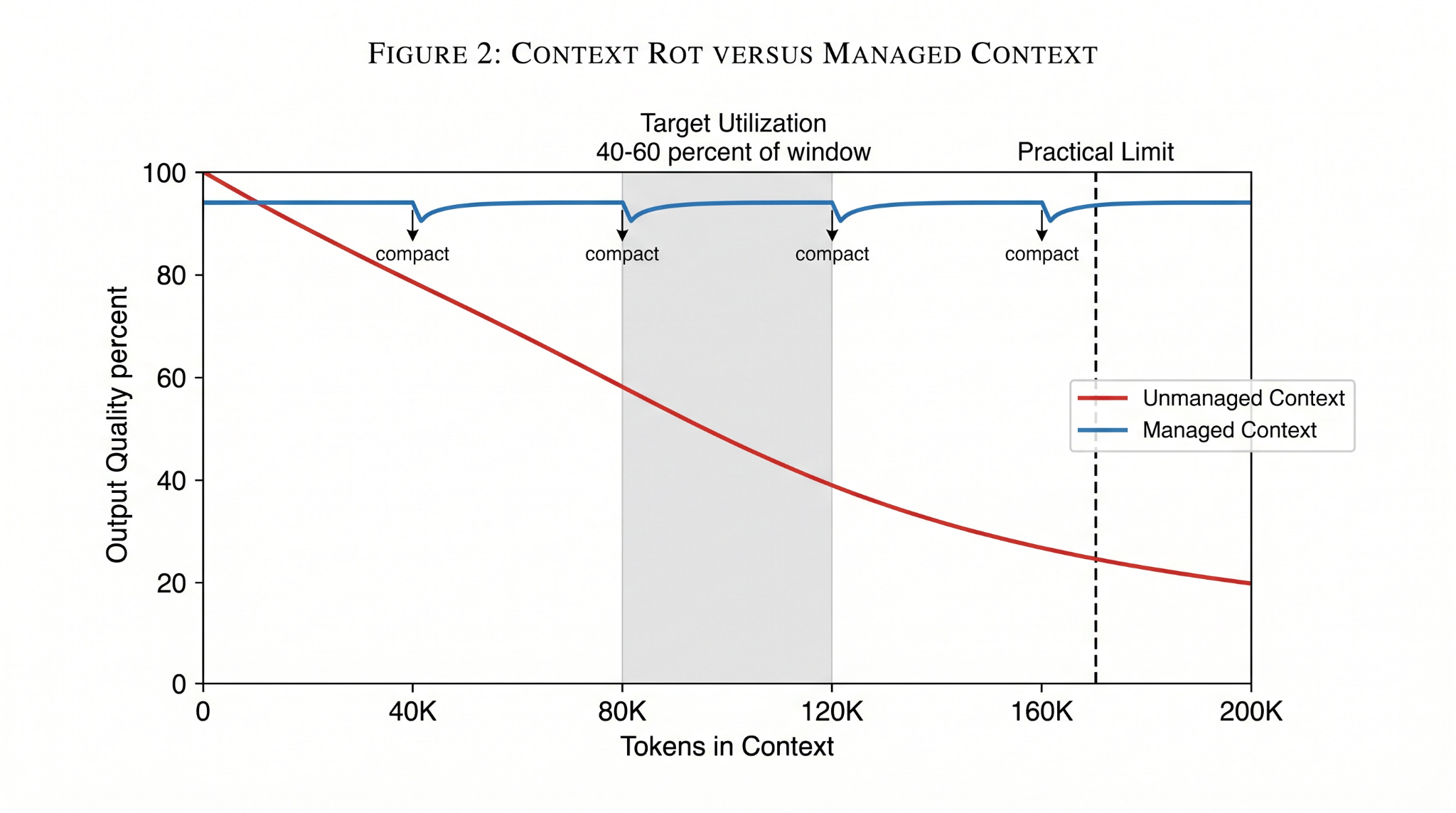
Geoff Huntley frames the budget as roughly 170k usable tokens before quality collapses. Every search result, every file read, every 40-line JSON blob from a tool call eats into that budget. Compaction is distilling that garbage into structured artifacts before it poisons the window.
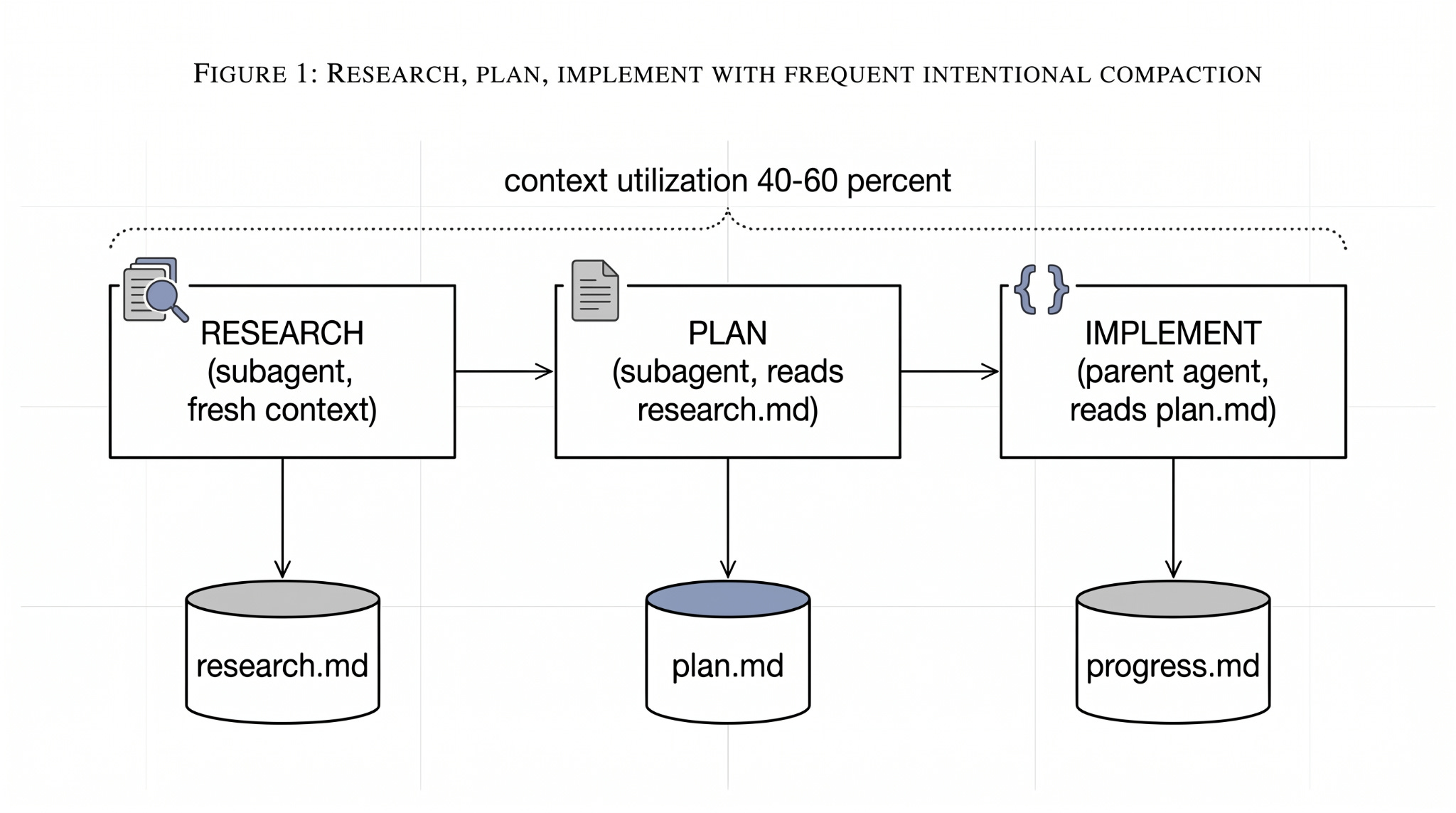
Research, plan, implement
Horthy’s workflow is three phases, each run with a fresh context window:
Research. A subagent maps the relevant files, understands how data flows, and writes a focused markdown doc. The parent agent never sees the grep output, the glob traces, or the 40 files it had to open to figure things out.
Plan. Using the research as input, produce an exact step-by-step plan: files to edit, testing approach, verification gates.
Implement. Step through the plan phase by phase, compacting status back into the plan file after each phase.
Target utilization: 40-60% of the context window. Past that, quality drops even if you haven’t hit the hard limit.
Subagents are not roleplay
This is the line worth tattooing. Subagents in Claude Code, Codex, and Amp are a context-control primitive, not a cute way to give your agent a “security expert” persona. You spawn a subagent so the 30k tokens it burns searching a codebase never enter the parent’s window. What comes back is a 1-2k token distilled answer. That’s it.
Put humans at the top of the pipeline
A bad line of code is one bad line. A bad line in a plan becomes hundreds of bad lines of code. A bad line in research -- a wrong mental model of how the system works -- becomes thousands of bad lines of code across multiple PRs.
So you put human attention on the research doc and the plan, not on line-by-line PR review. Code review stays useful for mental alignment across the team, but it stops being the load-bearing quality gate. The spec is.
Horthy’s team was spending about $12k/month on Opus across three engineers when he wrote the post. That number moves by a factor of two depending on which model you pick today, but the economics work -- if the plans upstream are good. Garbage plans just burn tokens faster.
What the last few months added
That was August 2025. Since then the field moved from “this is a workflow Dex figured out” to a measured research discipline with benchmarks, failure modes, and published primitives.
Context rot is now measured
Chroma’s late-2025 study tested 18 frontier models and formalized context rot: output quality degrades continuously as input length grows, well before the hard token limit. A model with a 200k window can show meaningful degradation at 50k. Morph’s March 2026 write-up summarizes it clearly -- the decline is a slope, not a cliff, and no model in the test set was immune. The “lost in the middle” pattern is part of it; attention dilution is another part.
Bigger windows don’t fix this. Shorter context does.
Compaction is now a first-class API feature
In March 2026, Anthropic shipped Claude Opus 4.6 with a Compaction API and Adaptive Thinking controls. The 1M token window got the headline, but the compaction primitive is the more important shift. Instead of every team writing their own “write progress.md and start a new session” logic, you can trigger a structured compaction step from the model provider itself. Anthropic’s cookbook on the tradeoffs walks through compaction vs. tool-result clearing vs. persistent memory and when each applies.
The tradeoff is still what Horthy flagged: aggressive compaction drops details whose importance you only discover later. You can’t automate your way out of picking what to keep.
Agentic Context Engineering: contexts as evolving playbooks
ACE, published at ICLR 2026, attacks a different failure mode. Classic summarization-based compaction has two problems: brevity bias (summaries drop domain-specific insights in favor of generic gist) and context collapse (iterative rewrites erode specifics over time until the context says nothing useful). ACE reframes context as an evolving playbook with three roles -- a Generator producing reasoning trajectories, a Reflector extracting insights from successes and failures, and a Curator integrating those insights as incremental structured updates rather than full rewrites.
Results: +10.6% on agent benchmarks, +8.6% on finance tasks. On AppWorld, a smaller open-source model running ReAct+ACE matched IBM-CUGA -- a production GPT-4.1 agent -- on average and beat it on the harder test-challenge split. ACE also works without labeled supervision by using natural execution feedback.
Stop thinking of context as a transcript to compress. Start thinking of it as a working document you curate over time.
Just-in-time retrieval beats pre-loading
Anthropic’s September 2025 post on effective context engineering argued that embedding-based pre-inference retrieval is being replaced by just-in-time strategies: the agent holds lightweight identifiers (file paths, query names, URLs) and pulls the actual data through tools when it needs it. Claude Code does this with glob and grep. Jentic’s JITT pattern extends the same idea to tool definitions -- you RAG over OpenAPI specs instead of front-loading 400 tool schemas.
Progressive disclosure is the umbrella term. The agent discovers what it needs layer by layer. File sizes suggest complexity, naming conventions hint at purpose, timestamps proxy relevance. It’s the Horthy research step generalized into a runtime pattern.
Autonomous memory control
Two arxiv papers from January 2026 pushed on a related question: can the agent manage its own context without external orchestration?
Focus (arxiv 2601.07190) is a slime-mold-inspired architecture where the agent autonomously decides when to consolidate learnings into a persistent “Knowledge” block and prune raw interaction history. On SWE-bench Lite with Claude Haiku 4.5, Focus cut tokens 22.7% while holding accuracy flat, with per-task savings up to 57%. Six autonomous compressions per task on average.
Agent Cognitive Compressor (ACC) (arxiv 2601.11653) replaces transcript replay with a bounded internal state updated online each turn. It separates artifact recall from state commitment, which means unverified content can’t silently become persistent memory. The paper shows lower hallucination and drift than both transcript-replay and retrieval-based baselines across IT ops, cybersec response, and healthcare workflow scenarios.
Both papers converge on the same finding: given the right tools and prompting, capable models will self-regulate context effectively. You don’t always need to drive compaction from the outside.
AGENTS.md is under scrutiny
A counter-intuitive one. ETH Zurich’s March 2026 paper measured what happens when you strip the context files that 60k+ open-source repos have adopted.
LLM-generated AGENTS.md files hurt performance. Task success rates dropped 3% on average while inference cost went up over 20%. The trace analysis showed agents dutifully following the instructions -- running more tests, reading more files, doing more grep searches -- and producing worse patches at the end.
The takeaway isn’t “no context files.” Auto-generated project context is noise. Human-written context files focused on non-inferable details (specific build commands, custom tooling quirks) were fine. The rest was polluting the window.
Multi-agent as context isolation, not division of labor
Anthropic’s multi-agent research system reportedly outperformed a single Opus 4 agent by 90.2% on research tasks. The architecture: Opus 4 lead delegating to 3-5 Sonnet 4 subagents in parallel, each with its own clean window. TechAhead’s April 2026 piece on context rot puts numbers on the failure mode -- degradation predictable after 20-30 conversation turns, 79% of multi-agent failures traced to coordination rather than model capability, just-in-time retrieval keeping context under 8k tokens improving accuracy.
Multi-agent wins come from clean per-agent windows, not from giving agents personalities.
Where the field converged
Aurimas Griciūnas’s State of Context Engineering 2026 names five patterns that stabilized: progressive disclosure, compression, routing, evolved retrieval, and tool-surface management. A March 2026 arxiv survey proposes five context quality criteria -- relevance, sufficiency, isolation, economy, and provenance -- and frames context as the agent’s operating system. Mem0’s State of AI Agent Memory 2026 covers the LOCOMO benchmark, which finally lets you compare memory architectures on the same evaluation set.
The vocabulary stabilized. You can now have a design conversation about context the way you used to have one about caching.
Horthy’s post was one engineer’s workflow. Eight months later it’s a discipline with benchmarks, failure modes, and production primitives you can actually deploy.
What to actually do
If you take context engineering seriously, the practical checklist:
Context window is a budget, not a buffer. Target 40-60% utilization. An LLM turn is a stateless function -- the contents of the window are the only lever on output quality. Past 60%, assume quality is degrading even if you haven’t hit the hard limit.
Split workflows into research, plan, implement. Run each with a fresh window. Compact between phases.
Use subagents for context isolation, not role-play. Spawn them to keep search, exploration, and tool-call noise out of the parent window. Return 1-2k token distilled summaries.
Put human review at the top of the pipeline. Review research docs and plans carefully. Stop treating line-by-line PR review as the primary quality gate.
Prefer just-in-time retrieval over pre-loading. Hold identifiers, pull content through tools at runtime. Same for tool definitions once you pass a few dozen.
Compact proactively and clear tool results aggressively. Trigger compaction before context fills, not after the model starts failing. Large JSON blobs, stale file contents, old search output -- drop them once the information is captured.
Treat context as an evolving playbook, not a transcript. Structured incremental updates beat full rewrites. Preserve specifics. Watch for brevity bias and context collapse.
Be skeptical of auto-generated project context. Keep only non-inferable details a human wrote. Delete the rest.
Isolate by default. Multi-agent wins come from clean per-agent windows, not from giving agents personalities.
Measure and stay engaged. Track tokens-per-task, compactions-per-task, success rate, and cost. No prompt, no workflow, no framework makes this work if the human isn’t steering the research and reviewing the plans. Horthy and Vaibhav sat DEEPLY ENGAGED for seven hours. That’s the job now.
The models will keep getting better. But for now, the person paying attention to what sits in the window is still the one shipping the code.