Return to the Competition
Day 16 of the OpenAI Parameter Golf Challenge

Article 6 of an ongoing series.
Day 1 begins here:
In Article 5, I hit sub-1.0 for the first time with an entropy-adaptive n-gram cache (0.9642 bpb), submitted six PRs including two diffusion models and a fused softcap+CE kernel, tested my own CoDA-GQA attention mechanism in competition conditions, and ran out of money. Five dollars left on the RunPod account. Competition over.
Then I woke up to compute credits in my inbox.
I need to back up.
The Rug Pull
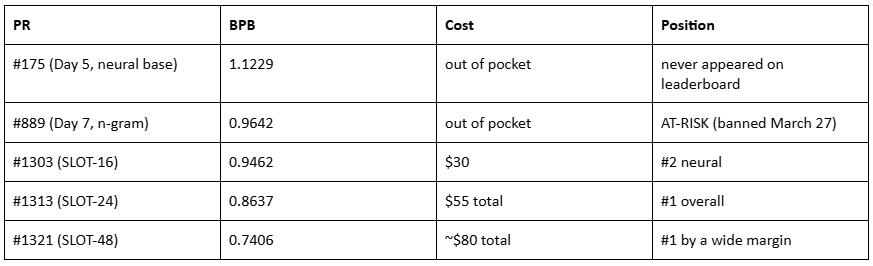
The day Article 5 went live, March 27, the organizers retroactively banned n-gram caching. PR #889, my sub-1.0 submission, moved to AT-RISK status. The achievement I’d written about that morning was invalidated by that evening.
PR #175, my pure neural submission at 1.1229, should have been sitting at #1 on the neural leaderboard. The official leaderboard hadn’t been updated since March 19. I couldn’t tell where I stood. Nobody could.
I applied for compute credits. Twice. Never heard back. The competition frontier kept moving without me. Other competitors reached 0.93 bpb using new techniques my research had unearthed but without guidance or money I was reluctant: SLOT, QK-Gain sweeps, Scylla tokenizer. I watched from the sideline with $5 on my account and a growing suspicion that this competition wasn’t designed for a 46-year-old independent consultant funding his own GPU time.
I pulled away. Six days of nothing.
Day 16
April 2. Email from RunPod and OpenAI. Compute credits, available immediately.
I didn’t have a plan. I’d mentally closed this chapter. But free H100 time is free H100 time, and I’d spent the past week reading every PR that went up while I was sidelined.
Two hours of research with my agentic system. The competition had changed. The big breakthrough was SLOT: Scored-position Learned Output Tuning. You freeze the trained model weights entirely, then optimize a tiny adapter (per-window delta plus logit bias) during evaluation. The model never changes. You just teach a small set of parameters to correct its predictions on each window of text. PRs #1176 and #1229 had the implementations.
Issue #140 on the repo had turned into a live AI commentary thread, auto-analyzing every submission in real time. The community had built its own research infrastructure around the competition.
Three hours of building. I took my PR #175 base (VRL + LeakyReLU^2, 1.1229 bpb) and integrated four techniques: SLOT from scratch based on the two reference PRs, QK-Gain 4.0, XSA on all 11 layers, and the sliding window improvements from the past week. 1,457 lines of code. Smoke-tested on a single H100. SLOT was working. Even on a barely-trained 20-step model, it knocked 0.023 bpb off the score.
Hit the artifact size cap at 16.1MB. Had to cut BigramHash from 2048 to 1024 buckets to squeeze under 16.
PR #1303. 8xH100, three seeds. 0.9462 bpb. #2 on the neural track.
From 1.1229 to 0.9462 with SLOT. That’s 0.177 bpb of improvement from eval-time optimization alone. The model architecture is identical to what I submitted on Day 5. Same weights. Same training. The only difference is what happens after training.
Cost: $30.
Seven Models, Three “Bugs”
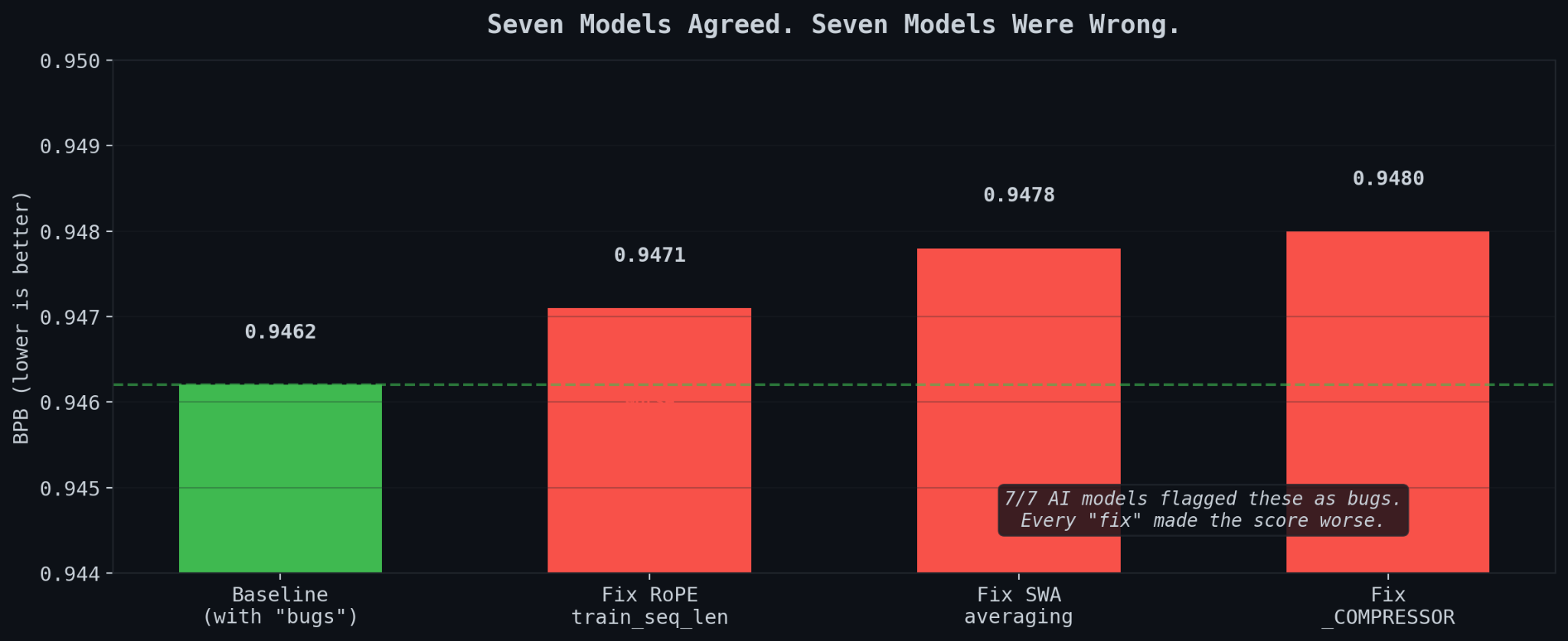
I sent the code to seven AI models for review. They unanimously found three bugs. RoPE train_seq_len hardcoded to 1024 instead of matching the 2048 eval context. Sliding window averaging never applied. _COMPRESSOR variable undefined.
I tested each fix. Every single one made the score worse. 0.9480 instead of 0.9462.
The RoPE “bug” was accidentally doing NTK-aware scaling, which helps at longer sequence lengths. The EMA at decay=0.997 worked better solo than blended with sliding window averaging. The undefined compressor was dead code that never executed.
Seven models agreed. Seven models were wrong. The only truth in ML is the number that comes back from the eval script.
The Hardware Lottery (Again)
Same discovery I wrote about on Day 6, but it bit me again. I spun up pods in three regions. Japan: 216ms/step. Canada: similar. India: 91ms/step.
Same GPU name. Same template. Same container. Same code. The India pod trains 2.4x faster, which means it sees 2.4x more data in the 10-minute window, which directly determines the bpb. The competition leaderboard is partly a hardware lottery. The top entries report 83-88ms/step. If you land on a 216ms pod, you are not competing.
New protocol, same as before: benchmark every pod for 20 steps. Kill anything over 120ms. At $21.52/hour, a bad pod costs $2 before you catch it. A good pod saves $15 in wasted training.
From #2 to #1
With a fast pod secured, I ran a 6-configuration hyperparameter sweep on SLOT. The variables: SLOT steps (how many optimization steps per window), learning rate, and evaluation stride.
The sweep found the signal. SLOT_STEPS=24, SLOT_LR=0.012, EVAL_STRIDE=96 was dramatically better than the SLOT-16 configuration I’d used in PR #1303.
Re-ran on a 93ms/step India pod. Seed 1337: 0.8683 bpb.
Three-seed validation: 0.8637 bpb. #1 overall in the entire competition.
Beat the previous best (PR #1229, 0.9300) by 0.066 bpb. Submitted as PR #1313. Total cost for both submissions: $55.
The difference between #2 and #1 was three numbers. The model architecture never changed. Same 27-million-parameter transformer, trained the same way every time. SLOT_STEPS=24, SLOT_LR=0.012, EVAL_STRIDE=96.
The Scaling Question
I kept pushing. SLOT-48 hit 0.7406 bpb across three seeds. Submitted as PR #1321. SLOT-64 hit 0.6633 on seed 1337.
Every research model I consulted predicted diminishing returns after 24-32 steps. The loss surface should flatten out. The information content of 96 tokens per window should be the bottleneck. The theoretical analysis was clear.
The theoretical analysis was wrong.
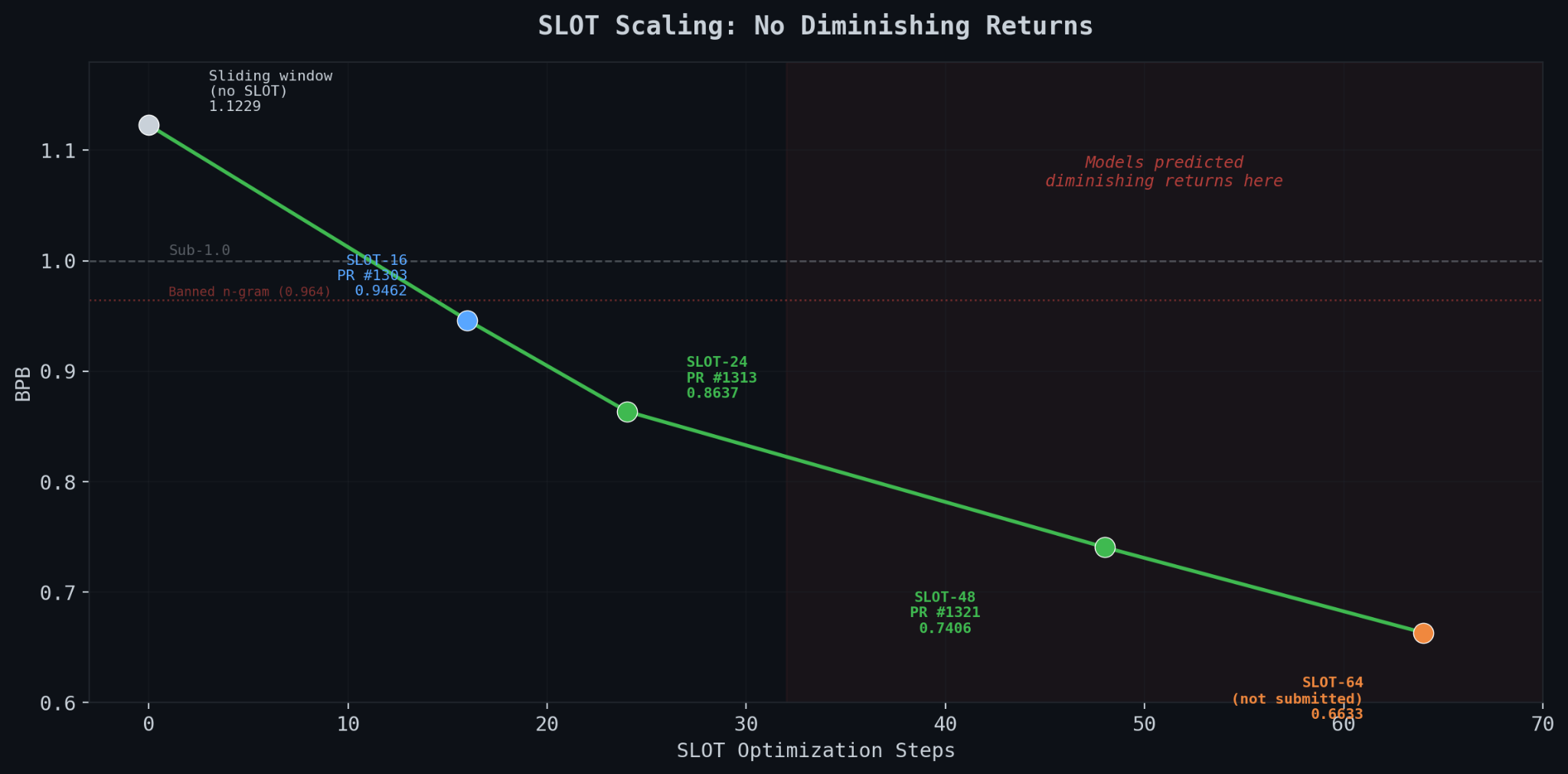

No diminishing returns through 64 steps. SLOT keeps finding structure in the hidden-state-to-logit mapping that takes many optimization steps to exploit. The models were wrong about the scaling. Again.
This raises a question I don’t have an answer to. At 64 steps, SLOT is fitting 1,536 parameters to 96 tokens per window. It compresses text to 0.66 bits per byte, better than the n-gram caches that got banned. The mechanism is different (frozen model plus tiny adapter versus explicit data tables), but the effect is similar. At some point, eval-time optimization becomes test-set memorization. I don’t know where that line is. The competition rules say “evaluation methods are unrestricted.” The community may draw a different line.
I didn’t submit SLOT-64. Too aggressive. PR #1321 with SLOT-48 at 0.7406 is where I stopped.
The Scoreboard

From “competition over” to #1 overall …. or so it seems... but the leaderboard is dated WAY behind the actual competition, and we don’t know which entries will be declared illegal. One afternoon. $80 of compute.
I tried an asymmetric encoder-decoder split from PR #1275. It made things worse (0.874 vs 0.864). Dead end. The VRL + U-Net skip connections in my architecture are designed for symmetric splits, and breaking that symmetry breaks the residual flow.
Then the legality question landed.
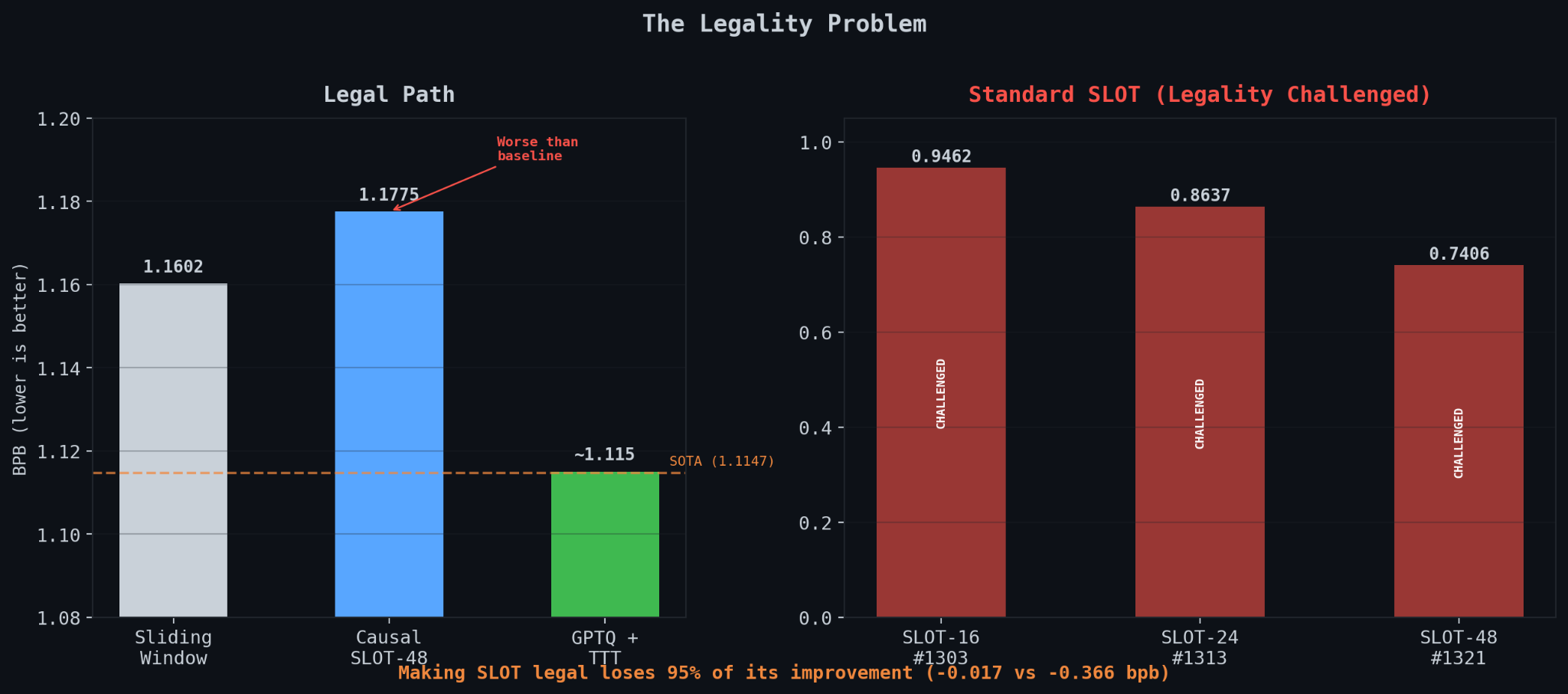
Someone opened Issue #1336: “Is context-only (causal) SLOT legal?” The argument went straight at the core of what I’d built. Standard SLOT optimizes its delta and logit_bias on the same tokens it then scores. The loss is computed over the last stride=96 tokens of each window, and after the optimization steps, those same tokens are evaluated with the optimized parameters. PR #1240 had already proven this violates Condition 1 from Issue #1017: flipping a target token changes predictions at other positions. That’s a causality violation.
The proposed fix was “causal SLOT.” Optimize the delta on positions 0 through (wlen - stride - 1), the already-scored context from prior windows. Only use the optimized delta to score the new tokens at the end. Same technique, same parameters, trained only on past data.
I implemented it. Three seeds on a fast pod. Causal SLOT-48: 1.1775 bpb. Our sliding window baseline without any SLOT was 1.1602. So causal SLOT gives -0.017 bpb of improvement, versus -0.366 for standard SLOT. The legal version loses 95% of its power.
This makes sense in hindsight. The whole value of SLOT is fitting the per-window distribution of the specific tokens being scored. If you can only fit the distribution of context that was already scored in prior overlapping windows, the delta is learning old information.
Meanwhile competitor @yahya010 forked our PR #1313, added Hessian GPTQ, and got 0.7271, beating our 0.7406 by 0.0135. Same standard SLOT, same legality questions hanging over it, just with better quantization.
If standard SLOT gets ruled illegal, my best submission becomes PR #175 at 1.1229. Still strong, probably #2 or #3 on the neural track, but it won’t beat the merged SOTA (PR #1019, @abaybektursun, 1.1147).
I spent the next day chasing every legal lever I could find.
Deep Delta Learning with Hourglass FFN. Replace the single 512-to-1536-to-512 MLP with two stacked 512-to-768-to-512 MLPs at the same parameter count. Three-seed test: 1.2615 bpb. A 0.139 regression. Wide MLPs beat stacked narrow ones at this scale. The halved hidden dimension’s expressiveness loss dominated any gain from the extra nonlinearity. Dead end.
OGD with Unigram Cache. Stride-OGD does online gradient descent on a vocab bias vector, updated per-window in a backward-looking manner. PR #384 had shown -0.003 bpb on a weaker model. I implemented it. Result: 1.333 bpb. A 0.211 regression. The batched sliding window processes 32 windows in parallel then updates the bias, which breaks the sequential assumption OGD needs. The bias becomes noise. Fixable but would require per-window sequential processing, which kills the speed advantage.
GPTQ with Hessian calibration. This actually worked. The merged SOTA uses autoregressive self-generated GPTQ: after training, the model generates 64 sequences of 2048 tokens from its own distribution, collects Hessians from forward hooks, then runs Cholesky-based error compensation during quantization. I ported the implementation from #1019 into our stack. Seeds 42 and 2024 landed at 1.1167 and 1.1171 on a fast pod. That’s 0.002 above merged SOTA. Below the 0.005-nat significance threshold.
The quant gap shrinks from 0.0075 (naive int6) to 0.0044 (GPTQ). The improvement is -0.003 bpb. Real but not enough.
I combined GPTQ with score-first TTT from PR #549: SGD with momentum 0.9, learning rate 0.001, 3 epochs per 32K-token chunk, all blocks unfrozen. Score each chunk with sliding windows first, then train on it. The gradient only uses tokens already graded, so it’s legal.
Launched the 3-seed run. Pod benchmarked at 94ms/step over 20 steps. Then the step time drifted: 95ms at step 10, 105ms at step 500, 113ms at step 1000, 122ms at step 1500. Thermal throttling or network contention. The pod was fine for a brief burst then degraded under sustained load.
I killed it at step 4,453 after the wallclock cap hit. A third fewer training steps than a stable pod would produce. Pre-quant bpb: 1.153, versus 1.137 on a clean run. Undertrained model, so GPTQ and TTT couldn’t compensate.
Killed the pod. Spun up another. Ran a sustained benchmark this time: 400 steps with the full 786K-token training batch, logging every 100 steps. Step time held at 90.7ms flat. That’s the pod you want. Not the 95ms-then-drift kind.
Three days in and the lesson is the same as Day 6: run a real benchmark, not a 20-step smoke test.
Two lessons from this week
I spent a day building three novel techniques: Deep Delta Learning, Hourglass FFN, Online Gradient Descent with unigram caching. Two regressed by 0.14-0.21 bpb. The third needed a sequential eval pattern that breaks batching. All three came from research papers that predicted 0.003-0.015 bpb improvements at this scale.
Then I ported an existing implementation from the merged SOTA submission. AR self-generated GPTQ. It worked immediately. Gave the predicted -0.003 bpb. Didn’t break anything.
Novel isn’t better. Novel is risky. In a tight competition with a strict compute budget, re-implementing what works beats inventing what might work. I already knew this from Articles 2, 3, and 4. Every week of this competition I relearn that being clever and being correct are different things.
The leaderboard doesn’t care whether your technique is original. It cares about the number.
I’m out of town for a week after this. The GPTQ+TTT results will land while I’m gone. Maybe they beat 1.1147 by enough to clear the significance threshold, maybe they don’t. Maybe Issue #1336 gets ruled and the SLOT submissions survive or die. Either way, PR #175 at 1.1229 is my floor. The pure neural submission from Day 5 that never appeared on the leaderboard but has held up through every technique change in this competition.
I’m out of money again, have a Happy Easter and I’ll see you next week.