Stop Letting Your Users Pick the Model
AI Product Engineering


Your Model Selector Is a Burn Rate Accelerator
There’s a dropdown in almost every AI SaaS product right now. You’ve seen it. GPT-4o, Claude Opus, Gemini Ultra. Pick your fighter. It feels like a feature. It’s a liability.
I’ve been building software products for over twenty years. I’ve shipped AI features for the last several. And I’m telling you: the model selector dropdown is one of the worst product decisions the AI SaaS industry has collectively made. It needs to go.
Not because users are dumb. Because incentives are misaligned, unit economics don’t survive contact with user behavior, and you can’t quality-control an experience when the most expensive variable is a user preference.
I’ve watched three separate AI startups burn through runway faster than projected because their users gravitated to the most expensive model in the lineup. Every time. The pattern is predictable, the outcome is predictable, and we keep building the same dropdown anyway.
The Math Doesn’t Work
Let’s get specific. Anthropic’s Claude Opus 4.6 costs $5 input / $25 output per million tokens. Haiku 4.5 costs $1 / $5. That’s a 5x spread within the same model family.
On OpenAI’s side it’s worse. GPT-5 Nano runs $0.05 / $0.40 per million tokens. O3-Pro runs $20 / $80. That’s a 400x cost difference. When your user picks o3-pro to summarize a meeting transcript that Nano handles fine, you just set 399 units of margin on fire.
If you give users a dropdown and one of those options is the biggest model available, which one do they pick?
They pick the big one. Every time. If you try and change it behind the scenes or tell it to use less effort, your users will find that out and they will complain that you are swindling them, even while you are losing money on every turn.
A developer on the Cursor forums described it well: they were spending more time deciding which model to use for each task than doing the actual work. Plan mode gets one model, implementation gets another, a quick CSS fix gets a third. The decision fatigue alone is a product failure. Most users skip the thinking entirely and just run everything on the most expensive option.
This isn’t speculation. Industry data backs it up: roughly 80% of coding tasks can be handled by cheaper, faster models. But teams default to premium models because they’re afraid of getting worse results. The same psychology applies to end users, except they don’t even see the bill.

The Jevons Paradox of AI
This is where the economics get ugly. Per-token costs dropped roughly 280x between 2023 and 2025. You’d think AI spending would flatten. It didn’t. Enterprise AI spending surged 320% over the same period.
Cheaper tokens didn’t reduce bills. They increased consumption.
Average enterprise AI budgets went from $1.2 million in 2024 to $7 million in 2026. Inference now accounts for 85% of enterprise AI budgets. Total inference spending jumped from $9.2 billion in 2025 to $20.6 billion in 2026. Some Fortune 500 companies are reporting monthly inference bills in the tens of millions.
Product leadership doesn’t want to hear this next part. AI SaaS gross margins sit at 50-60%. Traditional SaaS runs 80-90%. That gap is compute. It’s inference. And it’s made worse every time a user picks Claude Opus to draft a two-sentence Slack message.
OpenAI is the clearest proof this doesn’t scale. They generated roughly $12-13 billion in revenue in 2025 and posted a $7.8 billion operating loss in the first six months alone. Projected losses for 2026: $14 billion. They’re spending $1.35 for every dollar they earn. The largest AI company on the planet is proving in real time that all-you-can-eat inference at flat-rate pricing does not work. And they have SoftBank writing checks. You don’t.
Look at What’s Happening to Anthropic Right Now
Anthropic is one of the best-funded AI companies on the planet, and even they can’t make flat-rate premium model access work at scale.
In March 2026, Anthropic started throttling Claude usage during peak hours. Weekdays, 5:00 to 11:00 AM Pacific. Pro subscribers at $20/month, Max subscribers at $100 and $200/month, all got hit. During peak hours, your five-hour session limit burns faster than five hours. Off-peak, you get more.
Claude Code users reported burning through their entire Max plan quota in 19 minutes. One developer said they used up their Max 5 plan, the $100/month tier, in a single hour of work. Pro subscribers reported their accounts maxing out every Monday and not resetting until Saturday. Twelve usable days out of thirty.
Part of the problem: agentic workflows like Claude Code use 10-20x more tokens per task than a standard chatbot exchange. The product usage patterns shifted. The pricing model didn’t.
Anthropic’s own words: people are hitting usage limits “way faster than expected.”
This is what happens when you let users run the most powerful model for every task. The business model breaks. Not eventually. Right now, in real time, at one of the most well-capitalized AI companies in the world.
And Anthropic at least has the power to throttle. If you’re a SaaS startup wrapping Claude or GPT APIs and letting users pick the model, you don’t have that option. You just eat the cost. Or you raise prices. Or you run out of money.
The Model Selector Is a Product Design Failure
The model selector communicates one thing to users: “We don’t know which model is right for your task, so you figure it out.”
That’s an abdication of product responsibility. Your users aren’t ML engineers. They don’t know the performance characteristics of Haiku vs. Sonnet vs. Opus. They don’t know that Sonnet 4.6 handles 90% of professional writing tasks as well as Opus. They don’t know that Haiku can extract structured data from documents faster and cheaper than anything else in the lineup.
They see a dropdown, and they pick the one that sounds most powerful. The same way people pick the highest megapixel camera or the fastest processor on a spec sheet, whether they need it or not.
You built the dropdown because it felt like giving users control. What you actually did was hand them the keys to your cost structure with zero guardrails.
What Smart Companies Are Doing Instead
Route intelligently. That’s it.
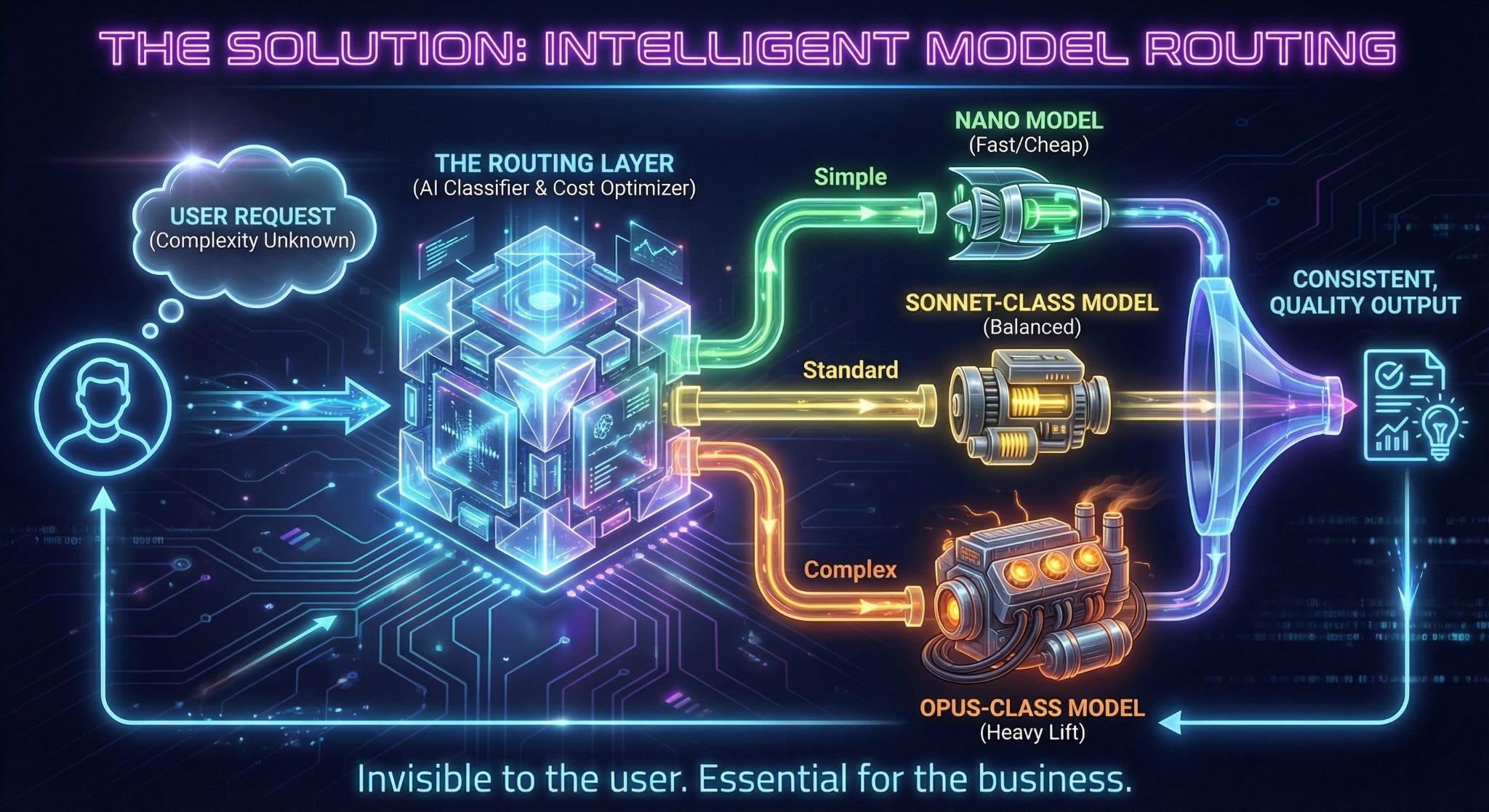
Enterprise LLM spending hit $8.4 billion in 2025. Organizations using intelligent model routing report 30-70% cost reductions while maintaining output quality. Some report up to 98% savings on specific workloads.
The mechanics aren’t complicated. A routing layer evaluates each request and sends it to the right model based on task complexity. Summarization goes to a small model. Complex multi-step reasoning goes to a big one. The user never sees a dropdown. They just get good results.
This is the same pattern every mature technology industry has adopted. You don’t pick which cell tower your phone connects to. You don’t choose which CDN node serves your Netflix stream. The system routes intelligently, and the user gets the right outcome.
AI SaaS should work the same way. Auto-selection can cut costs 50-80% without users noticing a quality difference. That’s not a minor optimization. That’s the difference between a sustainable business and a company subsidizing inference costs until the money runs out.
You Can’t QA What You Don’t Control
There’s another problem with the model selector that product teams don’t talk about enough: quality control.
When your user picks the model, you lose control of the output. Your prompt engineering was tuned for Sonnet. Your guardrails were tested on Sonnet. Your evaluation suite runs against Sonnet. The user switches to Opus, and now the tone is different, the verbosity is different, the formatting is different. They switch to Haiku, and the output is thinner than what your onboarding flow promised.
You can’t build a consistent product experience when a core variable changes based on user whim. It’s like shipping a web app where users can pick which version of React renders their dashboard. You’d never do that. But we’re doing the equivalent with models, and pretending it’s a feature.
Every model has different strengths, different failure modes, different behavioral patterns. If you’re serious about your product, you pick the right model for each task, you test it, you tune your prompts for it, and you own the output quality. That’s what product engineering looks like.
The Business Model Has to Change
Seat-based pricing dropped from 21% to 15% of AI companies in just twelve months. Hybrid pricing surged from 27% to 41%. Companies clinging to traditional per-seat pricing see 40% lower gross margins and 2.3x higher churn than those using usage-based or outcome-based models.
The pricing model is evolving because it has to. But the product model hasn’t caught up. You can’t charge per-seat and then let every seat burn Opus-tier tokens on tasks that need Haiku. You can’t charge per-outcome and then have zero control over the inference cost per outcome.
The model selector makes both of these problems worse. Remove it. Replace it with intelligent routing. Expose the routing logic to power users through an API or settings page if you must. But the default experience should be: send a request, get the right model, get good output.
Intercom figured this out. Their AI agent Fin charges $0.99 per resolved support ticket. No model selector. They route internally, optimize for cost per resolution, and price against business value. Over a million customer issues per week. $100M+ ARR. That’s what outcome-based AI product design looks like.
This Is a Product Problem, Not an AI Problem
I keep hearing people frame the cost of AI as a technology problem that will be solved by better hardware or cheaper models. That’s half right. Costs per token will keep falling. But as we’ve already seen, cheaper tokens don’t reduce spending - they increase it.
The other half is a product problem. And product problems require product solutions.
I’ve built AI applications where a single prompt redesign cut inference costs by 60% with no user-visible change. Seriously, it’s just clever engineering. I’ve seen routing logic that sends 70% of requests to a model that costs one-fifth as much, and users rate the output the same - and anyone that works at Openrouter can confirm this. These aren’t theoretical improvements. They’re engineering decisions that product teams should be making instead of punting to a dropdown.
The AI model IS NOT WHAT NEEDS TO CHANGE. Not the neural network.
What must change: The business model. The product model. The mental model that says users should pick their own inference tier like they’re ordering off a menu.
Stop treating model selection as a user feature. Start treating it as an infrastructure decision. Your users don’t want to pick a model.
They want their task done well.
The dropdown has to go.